An Open-Source ML Pipeline
Whether our model is predicting churn, detecting fraud, or forecasting sales, there are a few components that are common across any ML pipeline. In particular, every ML pipeline includes the following features:
- A feature store for model training and inference
- Many CI/CD validations to detect changes in those features
- An experimentation environment for logging previous model runs and metrics
- A model registry for serving and version controlling production models
- A service for tuning hyper-parameters efficiently
- A service for model monitoring for automatic model retraining, data drift detection, and reporting
Using Feast as a Feature Store
A feature store is an API best used for low-latency feature retrieval for real-time models being served in production. A feature store plugs into your existing storage infrastructure and orchestrates jobs using your existing processing infrastructure, so it is not a database in most cases. Usually, a feature store takes already transformed features (from Azure Data Lake, AWS Redshift, Snowflake, etc.) and generates feature definitions and metadata for them, in order to improve the performance of the feature retrievals.
A feature store is used for maintaining features across different data sources in a single, centralized location. Doing this promotes a central catalog for all features, their definitions, and their metadata, which allows data scientists to search, discover, and collaborate on new features. Two common and open-source feature stores are Feast and Tecton. For more detailed use-cases surrounding feature stores, refer to Feast's documentation and Tecton's documentation, which are two of the most common and open-source feature stores.
In Feast's feature store, a feature store comes with two components: a registry and feature stores. The default Feast registry is a file-based registry, where feature definitions, metadata, and versions are tracked in your local file system under a file named registry.db. In production, Feast recommends using a more scalable SQL-based registry that is backed by a database, such as PostgreSQL or MySQL. The registry more specifically holds feature views. A feature view is an object that represents a logical, unmaterialized group of features consisting of the following information:
- The data source
- The specified features
- A name to identify this feature view in Feast
- Any additional metadata, like schema, description, or tags
The second component within Feast is the feature store, which can be an offline store or an online store. The offline store persists batch data from feature views. By default, the offline store will not log features and will instead run queries against the source data. However, offline stores can be configured to support feature writes to an offline destination. An online store is a database that stores only the last values for real-time inference. The online store is populated through materialization jobs from an offline store.
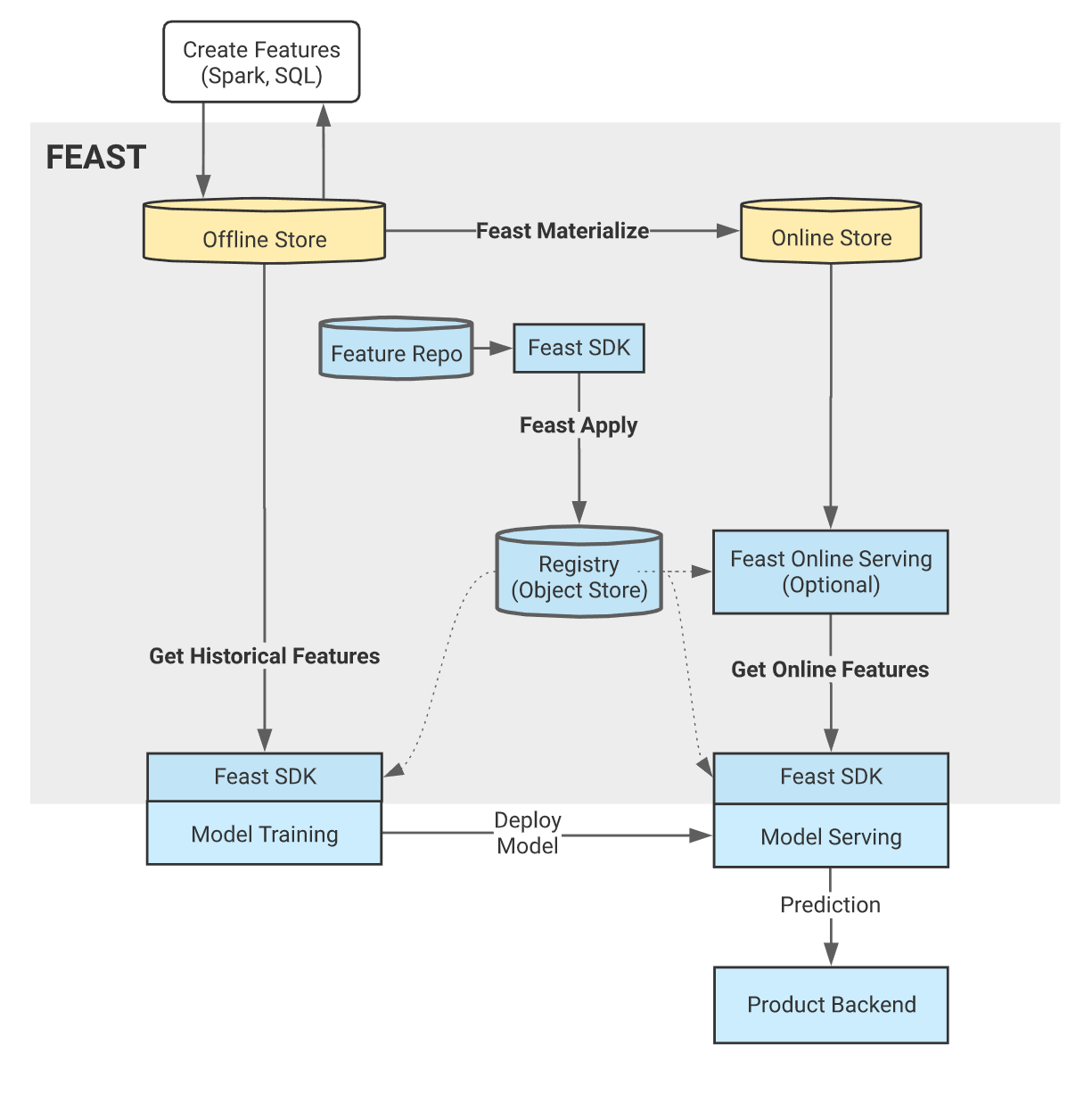
The offline store is preferred for fetching features when training a model or making daily or weekly predictions. On the other hand, the online store is preferred for fetching features when making real-time predictions (e.g. fraud detection). For more details about the feature registry, refer to their registry documentation and documentation about feature views. For more details about the various feature retrieval patterns, refer to their documentation.
Using Great Expectations for CI/CD Data Validations
Great Expectations is an API used for testing, profiling, and documenting expected feature properties, including expected value ranges and data types. The data profiler will automatically generate its own expectations in a report, illustrating example values, percentages of missing values for columns, histograms of numeric columns, etc. Manual tests can be included as well, which could include allowed column values, thresholds of null percentages before sendings warnings, etc. Great Expectations can be scheduled and orchestrated in a CI/CD pipeline using Airflow or Kubeflow.
By default, Feast uses Great Expectations as a validation engine and data profiler. As a result, we can specify the expected data types and value ranges for input columns. For a detailed example of using Great Expectations with Feast, refer to their documentation.
Using MLflow for Model Registry and Experiment Tracking
A model registry is a centralized object store that stores binary model objects with any metadata. By default, the model registry typically is stored in the local file system or a SQL database, but a remote object store also can be specified (e.g. AWS S3, ADLS, GCS, etc.). The metadata that is stored with the models could include model versions, stages, registry dates, and tags.
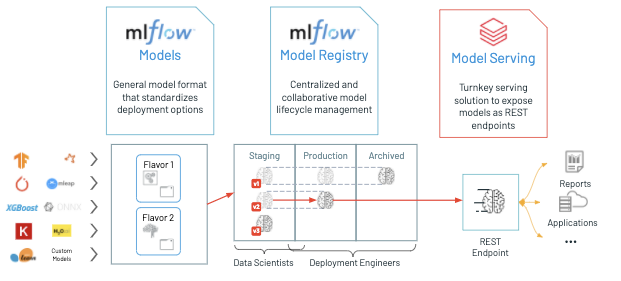
MLflow is one example of a model registry that documents a model's lifecycle. For example, MLflow will document the model versions and allow for the model to have different stages. Registered models can be in the production stage, staging stage, or archived stage. The production stage is meant for production-ready models serving inference, whereas the staging stage is meant for a pre-production model that is meant for testing and intended to be put into production in the future. Archived models are meant for previous models in production. For more details about the model registry component in MLflow, refer to the documentation.
Mlflow registers models that have gone through experimentation. A model experiment tracks and logs previous model runs with any specified metrics, hyper-parameter choices, training date, and other metadata. By doing this, we can compare previous model runs with each other by observing their feature importances, accuracies, hyper-parameters, etc. A tracking UI comes with MLflow, which allows you to visualize these model runs and download model artifacts or metadata. Refer to the MLflow documentation for more details about logging experiments in Mlflow.
Using Hyperopt for Distributed Hyper-Parameter Tuning
When logging model runs in an experiment, hyper-parameter searches can be logged using GridSearch or other packages like Hyperopt. Hyperopt is an API that facilitates distributed hyperparameter tuning and model selection. Hyperopt allows models to scan a set of hyperparameters across a specified or learned space.
The basic steps when using Hyperopt are the following:
- Define an objective function to minimize
- Define the hyperparameter search space
- Specify the search algorithm
- Run the Hyperopt function fmin()
In most cases, the objective function is the training or validation loss function.
Hyperopt uses stochastic tuning algorithms that perform a more efficient search of hyperparameter space than a deterministic grid search. The fmin function executes a run by identifying the set of hyperparameters that minimizes the objective function. The fmin function accepts the objective function, hyper-parameter space, and an optional SparkTrials object. The SparkTrials object allows you to distribute each HyperOpt iteration from a single-machine tuning to the other Spark workers. For more high-level use-cases about Hyperopt, refer to the documentation in Databricks. For more details about the components of Hyperopt, refer to the documentation in Databricks.
The objective function is where we implement the training portion of the code, where a dictionary is returned with the desired loss function and status. For more details about SparkTrials, refer to the Databricks documentation. For more examples about defining a function for optimization, refer to the Hyperopt documentation. Note, if you're experiencing issues with memory, you may benefit from loading in the training/validation data as binary objects instead, since Hyperopt can be memory intensive. For a sample objective function, refer to the following code snippet:
# Initialize possible hyper-parameter space for tuning
space = {
'learning_rate': hp.choice('learning_rate', [0.01, 0.02, 0.06, 0.08, 0.1]),
'max_depth': hp.choice('max_depth', [3, 4, 5, 6, 7, 8]),
'objective': 'reg:squarederror',
'n_jobs': 10,
'random_state': 3
}
# Initialize objective function iterating over hyper-parameter space
def objective(space):
# Autolog model details and signatures for each child run
mlflow.xgboost.autolog()
with mlflow.start_run(run_name=run_name, tags=tags, nested=True):
# Load in training and test data from DBFS saved above to preserve memory
train = xgb.DMatrix('/dbfs/FileStore/shared_uploads/darius_kharazi@anfcorp.com/train.buffer')
validation = xgb.DMatrix('/dbfs/FileStore/shared_uploads/darius_kharazi@anfcorp.com/validation.buffer')
# Initialize and fit model with different combinations of tuned hyper-parameters
model = xgb.train(params=space, dtrain=train, evals=[(validation, "validation")])
# Fit model and predict on test data
test_y_ltv_pred = model.predict(validation)
# Calculate accuracy metrics
r = round(mean_squared_error(validation.get_label(), test_y_ltv_pred, squared=False), 3)
m = round(mean_absolute_error(validation.get_label(), test_y_ltv_pred), 3)
# Log RMSE and MAE metrics to mlflow experiment
mlflow.log_metric('rmse', r)
mlflow.log_metric('mae', m)
# Return RMSE for hyperopt optimization
return {'loss': -r, 'status': STATUS_OK}When defining hyper-parameter ranges within a search space, use helper functions implemented in Hyperopt. Memory issues may appear if the ranges for particular hyper-parameters are too large. The SparkTrials objects is available to make use of distributed hyper-parameter tuning. For additional tips about defining a search space, refer to the Hyperopt documentation.
Using Evidently for Model Monitoring
Model monitoring involves maintaining registered or production-ready models and their metrics, data values, and other properties. Model maintenance can often be costly, since it impacts every data scientist and requires manual analysis about when and why accuracies worsen over time. The quality of a model in production can decline over time for many different reasons. For example, inventories could change over time, customer preferences could change over time, and regional changes could happen. Automating the model monitoring process offers the following benefits:
- Automates the model retraining process
- Automates metric and accuracy analysis
Evidently is an API that detects and alerts when there are changes in a model's quality. Evidently ensure models are retrained after a model drops below some accuracy threshold, which is manually assigned by the user. Evidently also saves and tracks any specified metrics and statistics for each model, which will be illustrated through visual reports.
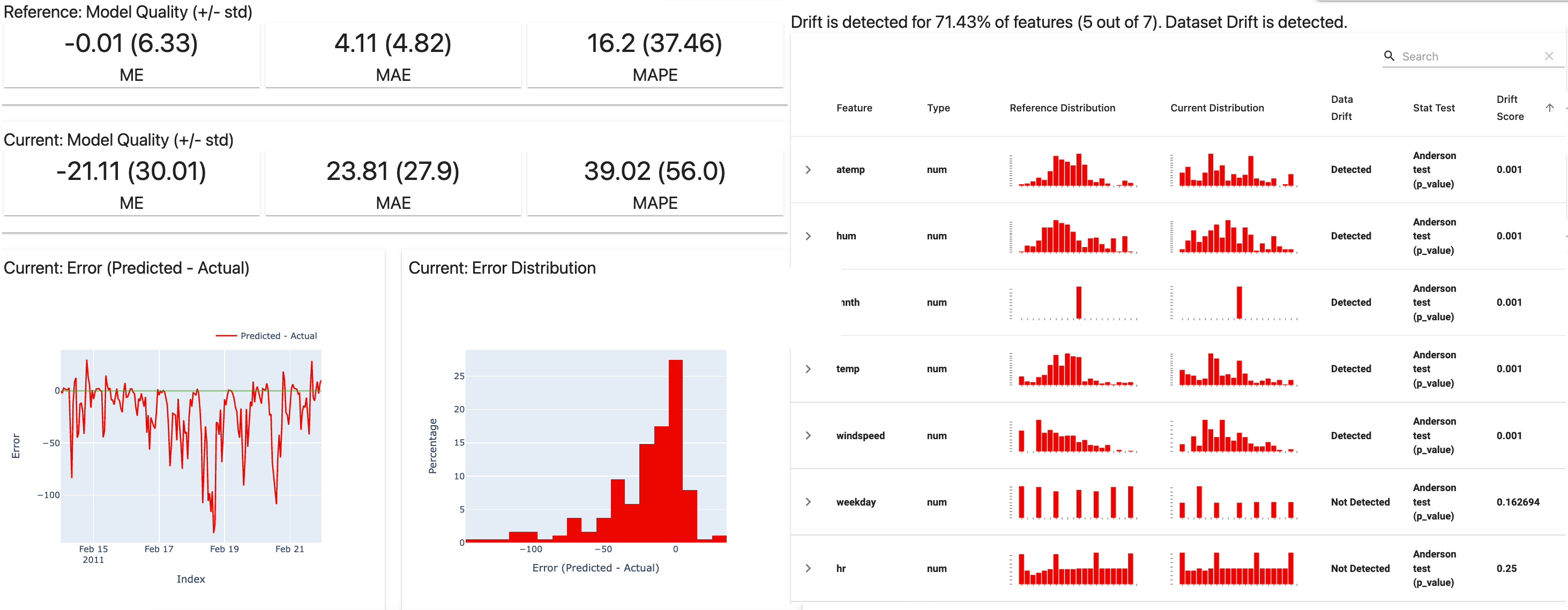
Statistical tests to compare the input feature distributions can be triggered automatically, while alerts can be emailed alongside visual reports illustrating any drifts in the input features. By doing this, we can understand why model accuracies have changed over time based on drifts in the inputs. This highlights a common problem within model monitoring known as data drift, which specifically refers to distributional changes of any input features that a model is trained on. On a similar note, target drift may also occur, which refers to distributional changes of any model outputs (or predictions). Target drifts are caused by changes in the model inputs in most cases. For high-level details about model monitoring, refer to this webinar illustrating the occurrence of model staleness in production. For a detailed walkthrough of setting up and using Evidently for model monitoring, refer to this example in their documentation.