NoSQL Basics: Graph Databases
In a previous post about NoSQL databases, graph stores were described at a fairly high-level. In this post, we'll dive into more low-level details, which includes features, behavior, and use cases.
NoSQL Distilled is a terrific resource for learning about both high-level and low-level details of NoSQL databases. This post is meant to summarize my experience with these databases, along with particular segments from the book. Again, refer to the book for a deeper dive of relational and NoSQL databases.
Table of Contents
Defining a Graph Store
Graph databases store two types of objects:nodes and relationships. These nodes represent data entities, and replationships represent a relation between two entities. These relationships visually are represented as edges between two nodes. Each edge between entities has a direction and properties as well. In the world of graph databases, edges can be thought of as a series of joins.
Graph databases were designed to handle data with many relatonships. Roughly, relational data involving many different joins may be better suited in a graph database, since relationships are stored more efficiently. Graph databases intuitively manage relationships better than relational databases, since relationships are stored as objects themselves. As a result, lookups between tables for person ID and department ID don't need to be performed constantly, in order to find which person connects to which department. In other words, the relationships don't need to be inferred anymore.
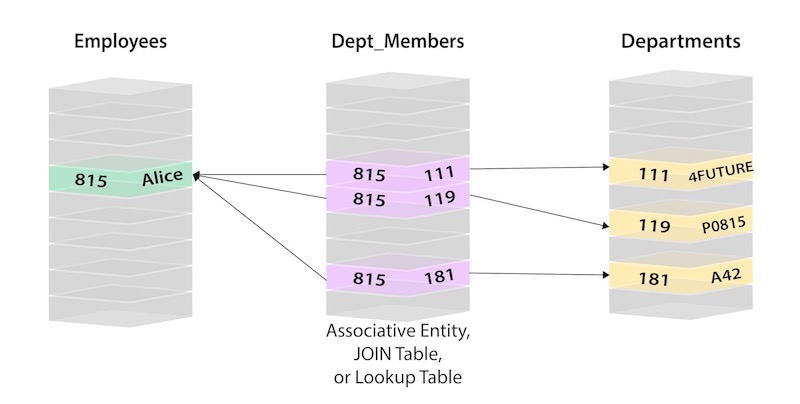
This ability to pre-materialize relationships into the database structure allows Neo4j to provide performance of several orders of magnitude above others, especially for join-heavy queries, allowing users to leverage a minutes to milliseconds advantage.
Neo4j offers a declarative graph query language, which is built on the basic concepts and clauses of SQL. Additionally, there are many other functions to simplify the process of working with graph models. Here is a SQL query:
SELECT name FROM Person
LEFT JOIN Person_Department
ON Person.Id = Person_Department.PersonId
LEFT JOIN Department
ON Department.Id = Person_Department.DepartmentId
WHERE Department.name = "IT Department"And this is the corresponding Cypher query:
MATCH (p:Person)-[:WORKS_AT]->(d:Dept)
WHERE d.name = "IT Department"
RETURN p.nameNotice, the query simplifies the heavy-use of joins. Not only does Neo4j simplify this process, it also improves the performance of join-heavy queries compared to SQL. The relationship between nodes is not calculated at query time, but it actually is persisted to disk. In relational databases, adding another relationship involves intricate changes to the schema. However, this becomes much simpler in Neo4j.
For a more detailed comparison between graph and relational databases, refer to the Neo4j docs.
Features of Graph Databases
Similar to relational databases, most graph databases are ACID-compliant. Meaning, only valid transactions are individually committed to the database, even in the event of a failure. If a transaction isn't marked as finished or successful, then it will be rolled back.
Most graph database solutions aren't able to be distributed across multiple servers, favoring consistency and availability. A few graph databases, such as Infinite Graph, support node distribution across a cluster of servers, such as Infinite Graph. Whereas, Neo4j is implemented using a master-worker architecture that is fully ACID-compliant.
As emphasized already, graph databases handle data with complex relationships quite efficiently, since relationships are indexed themselves. Therefore, an RDBMS should be preferred if we're mainly interested in filtering individual entities. Graph databases should mainly be used if we're querting relationships.
Graph databases are useful for reading relationships, rather than writing and rarely reading these relationships. Specifically, other databases should be preferred if we're looking to write data and don't expect to query our stored entities or relationships often.
As opposed to relational databases, graph databases are fairly robust for data that is constantly changing. Specifically, graph databases can add relationships and properties, since graph databases can change traversing requirements without having to change its nodes or edges.
In other words, relational databases may be a preferred choice if the columns of a table aren't expected to change. Otherwise, graph databases may be a preferred choice if the requirements are expected to morph over time.
Graph databases are useful when searching throughout graph for a particular relationship. A graph database is optimized for traversing the graph for a relationship. If we're mainly interested in querying entities without a specific relationship in mind, a relational database may be better suited for our needs.
As an example, a graph database is useful when we're wondering what people Jennifer knows. On the other hand, a graph database may not be very useful when we're wondering who Jennifer knows. A good query for a graph database is:
MATCH (n:Person {name: 'Jennifer'})-[r:KNOWS]->(p:Person)
RETURN pSince the map would need to be traversed entirely, a poor query for a graph database is:
MATCH (n)
WHERE n.name = 'Jennifer'
RETURN nIt should go without saying, but graph databases don't perform well when used as key-value stores. A standard lookup operation is best used for a key-value database or even a relational store. Graph databases are more useful for narrowed-down relationship lookups of a key.
Graph databases are performant when reading and writing smaller nodes. Graphs are not suited for storing many properties on a single node. They are also not suited for storing large values within those properties. This is because the query can hop from entity to entity quickly. However, graph databases need extra processing to pull out details for each entity along a search path. For additional summaries about features within graph databases, refer to this article.
Using Graph Databases
The table below outlines a few particular use cases for graph databases. In particular, the graph databases use Neo4j as a representative of the following use cases. Read more details about the Neo4j use cases in the docs. For more details about individual use cases, refer to the NoSQL Distilled text.
| Use-Case | Good or Bad? |
|---|---|
| Connected Data | Good |
| Social Network Data | Good |
| Delivery Routing | Good |
| Location-Based Services | Good |
| Recommendation Engine | Good |
| Fraud Detection System | Good |
| Updating all or some entities | Bad |
| Complicated operations | Bad |
| Large data | Bad |