Introducing Guidelines for System Design Interviews
-
System design interviews (SDIs) can be hard for reasons:
- SDIs are unstructured, open-ended, and have multiple solutions
- Candidates lack experience in developing complex systems
- Candidates did not spend enough time preparing for SDIs
- In FAANG companies, candidates must perform above average in coding interviews to receive an offer
- A good performance always results in a better offer, since it proves the candidate’s ability to handle a complex system
-
Most design problems can be solved using general steps:
- Clarifying requirements
- Roughly estimating scale
- Defining the system interface
- Defining the data model
- Drawing a high-level design
- Describing major components in detail
- Identifying any bottlenecks
-
The above steps can be translated to the following higher level objectives:
- Clarifying requirements
- Estimating scale
- Defining basic functionality
- Defining basic data flow
- Drawing the high-level design
- Detailing key components
- Identifying alternative solutions
Step 1: Requirement Clarification
-
Ask questions about system requirements
- Ask for functional requirements, non-functional requirements, and any extended requirements
- Functional requirements refer to user expectations directly related to the primary function of the system
- Non-functional requirements refer to user expectations indirectly related to the system (e.g. consistency, availability, security, etc.)
- Extended requirements refer to nice-to-haves
- Ask questions about parts of the overall system
- Ask questions about the goal of the system
-
Try forming questions around the following:
- What are the components of the system (i.e. classes)?
- What are the properties and behaviors of each component (i.e. attributes and methods)?
- How do our components interact with each other?
-
The following are examples of good questions:
- Will our service have users?
- Will our service have tweets?
- Are tweets created by users?
- Can users follow other users?
- Will tweets contain photos and videos?
- Are we developing for the back-end and front-end?
- Can users search for tweets?
- Will users receive push notifications?
- Should we display trending topics?
Step 2: Back-of-the-Envelope Estimation
-
Traffic Estimations:
-
Estimate expected traffic variables:
- Expected reads per month
- Expected writes per month
-
Do the following conversions:
- Reads per second by
- Writes per second by
-
-
Storage Estimations:
-
Estimate expected storage variables:
- Expected number of years until writes are purged
- Expected data size of one packet/write
- Are storage requirements different for images and video?
-
Do the following conversions:
- Total writes stored by
- Total storage size by
-
-
Network Estimations:
-
Do the following conversions:
- Expected read bandwidth by
- Expected write bandwidth by
-
-
Memory Estimations:
-
Estimate expected storage variables:
-
Expected percentage of data that is cached
- 80-20 rule says
-
How long should data be cached?
- Usually, it's a day
- Is less cache needed if there is redundant read requests?
-
-
Do the following conversions:
- Reads per day by
- Total cache size by
-
-
High-level Estimations:
- Number of new tweets per second?
- Number of tweet views per second?
- Number of timeline generations per second?
Step 3: System Interface Definition
- Define the required API calls expected from our system
- Typically, a REST API will be used for exposing the functionality of our service
- The following are examples of API calls:
# Users must be able to post a tweet
postTweet(user_id, tweet_data, tweet_location, user_location, timestamp)
# Timelines must be generated
generateTimeline(user_id, current_time, user_location)
# Users must be able to be favorited
markTweetFavorite(user_id, tweet_id, timestamp)Step 4: Defining a Data Model
- Defining a data model or database schema will help guide any conversation about partitioning or data management
-
First, describe high-level observations about the nature of the data we're storing
- E.g. how large is each record
- E.g. what is the relationship like between records
- E.g. will we need to handle more reads than writes
- Then, identify various key system entities or tables
-
Lastly, define what type of database we'll want to use:
- E.g. should we use NoSQL or RDBMS?
- E.g. what kind of block storage should we use to store photos and videos?
- Throughout the process, we must define different aspects of data management, like storage, transportation, and encryption
- The following is an example of a data model:
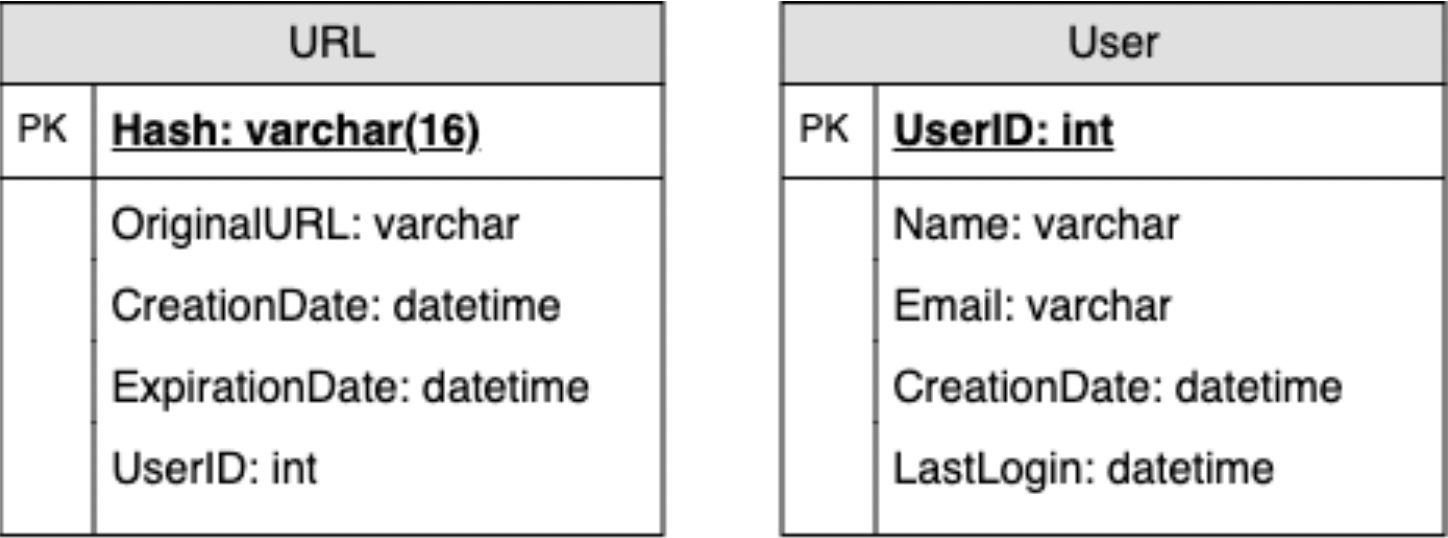
Step 5: Drawing a High-Level Design
- Draw a block diagram with at least boxes representing core components of the system
- Identify enough components that are necessary to solve the problem from end to end
-
As an example, for a system at Twitter we would need to think about the following for the front end:
- Using a load balancer to distribute read/write requests from users to multiple application servers
- Using a separate application server for receiving read requests and a separate server for write requests from the load balancer
-
Furthermore, for a system at Twitter we'd also need to think about the following for the back end:
- Using an efficient database that can handle a large number of writes (tweet posts)
- Using an efficient database that can handle a large number of reads (view others' tweets)
- Using a distributed file storage system for storing photos and videos
- The following is an example of a corresponding diagram:

Step 6: Describing Design in Detail
- Dig deeper into 2-3 major components
- The interviewer’s feedback should guide us to what parts of the system need further discussion
-
We should discuss the following for each component:
- Alternative approaches
- Tradeoffs for each approach
- Why we chose our final approach over others
-
The following are questions we could explore in this step:
- Should we distribute our data to multiple databases or use one database?
- What are ways we can partition our data if we're using multiple databases?
- What issues could be introduced by certain partitioning methods?
- How will we highly active users and less active users differently?
- When should we cache users' data?
- How much cache should we use for certain users?
- What components need better load balancing?
Step 7: Identifying and Resolving Bottlenecks
- Continue to think about alternatives to the major components
- Continue to identify tradeoffs and bottlenecks to each approach
-
The follow are examples of questions that should be addressed:
- Is there any single point of failure in our system?
- How are we mitigating any potential single point of failure?
- Do we have enough replicas of our distributed data in case we lose servers?
- Do we have enough copies of different services running so a few failures will not cause a total system shutdown?
- How are we monitoring the performance of our service?
- Do we get alerts whenever critical components fail or degrades?