Describing Max Pooling
- Max pooling attempts to create an abstract representation of an image using fewer dimensions
- For each iteration of convolution, max pooling involves calculating the maximum value from the portion of values covered by the filter
- We take the max of certain regions in order to detect some feature (given by a filter) in our input image
- A high value tends to indicate that a feature exists in that region
- This will reduce the dimensionality of an input image
-
Meaning, max pooling layers benefit in the following ways:
- They are less prone to overfitting (i.e. accuracy benefit)
- They don't require parameter learning (i.e. speed benefit)
Introducing Common Pooling Methods
-
There are two forms of pooling:
- Max pooling
- Average pooling
- Average pooling is rarely ever used
- Average pooling is only sometimes used to reduce the dimensions of an image, while attempting to best capture the image's properties
Implementing Max Pooling
- Max pooling doesn't rely on any learnable parameters
-
Instead, max pooling only relies on the following hyperparameters:
- : The size of the filter in the layer
- : The amount of padding in the layer
- : The stride in the layer
- We almost always set
-
The most common choices of hyperparameters are the following:
- and (and )
- and (and )
- An input image will have the following dimensions:
- An output image will have the following dimensions:
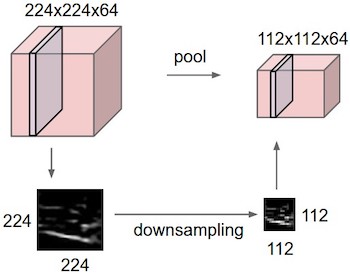
- The follow is an example of max pooling:

tldr
- Max pooling attempts to create an abstract representation of an image using fewer dimensions
- For each iteration of convolution, max pooling involves calculating the maximum value from the portion of values covered by the filter
- We take the max of certain regions in order to detect some feature (given by a filter) in our input image
- A high value tends to indicate that a feature exists in that region
- This will reduce the dimensionality of an input image
-
Meaning, max pooling layers benefit in the following ways:
- They are less prone to overfitting (i.e. accuracy benefit)
- They don't require parameter learning (i.e. speed benefit)
References
Previous
Next