Motivating the Transformer Model
-
An RNN has problems stemming from their sequential architecture:
-
Information loss
- Although GRU/LSTM mitigates the loss, the problem still exists
-
Suffers from the vanishing gradient problem
- Specifically, the problem caused by longer input sequences
-
Enforces sequential processing of hidden layers
- Parallelizing RNN computations is nearly impossible
-
-
The more words we have in our input sequence, the more time it takes decode the sequence
- The number of steps is equal to
-
Whereas, transformers support the following benefits:
-
Information loss isn't a problem
- Since, attention scores are computed in a single step
-
Don't suffer from the vanish gradient problem
- Specifically, the problem caused by longer input sequences
- This is because there is only one gradient step
-
Doesn't enforce sequential processing of hidden layers
- Parallelizing these computations is much easier
- Since, they don't require sequential computations per layer
- Meaning, they aren't dependent on previous layers
-
Describing the Basics of a Transformer
- A transformer uses an attention mechanism without being an RNN
- In other words, it is an attention model, but is not an RNN
- A transformer processes all of the tokens in a sequence simultaneously
- Then, attention scores are computed between each token
- A transformer doesn't use any recurrent layers
- Instead, a transformer uses multi-headed attention layers
Introducing the Architecture of a Transformer
-
A transformer consists of basic components:
- Positional encoding functions
- Encoder
- Decoder

Defining Positional Encoding Functions
- An input embedding maps a word to a vector
-
However, the same word in a different sentence may carry a new meaning based on its surrounding words:
Sentence 1:I love your dog!Sentence 2:You're a lucky dog!
- This is why we use positional encoding vectors
-
A positional encoding vector adds positional context to embeddings
- It adds context based on the position of a word in a sentence
-
Where the formula has the following variables and constants:
- is the position of a given word in its sentence
- is the index of the element of the word embedding
- is the size of the word embedding
- The following is an example of applying the positional encoding function to the -dimensional word embedding of dog:
Initial Steps of the Encoder
-
So far, we've completed the following steps, including:
- Embedding our input
- Performing positional encoding on the embedding
- Now, we're ready to pass the positional encoding into the encoder
-
This includes performing the following specific steps:
- Multi-head attention
- Normalization
- Feed-forward
- Before introducing multi-head attention, let's first start off by defining self-head attention
Types of Attention in Neural Networks
-
There are general types of attention:
- Encoder/decoder attention
- Causal self-attention
- Bi-directional self-attention
- For encoder/decoder attention, a sentence from the decoder looks at another sentence from the encoder
- For causal attention, words in a sentence (from an encoder or decoder) look at previous words in that same sentence
- For bi-directional attention, words in a sentence (from an encoder or decoder) look at previous and future words in that same sentence
- Neither of these attention mechanisms are mutually exclusive
- Meaning, any attention layer can incorporate any of the types of attention

Introducing Self-Head Attention in the Encoder
- Attention is how relevant the word in the input sequence relative to other words in the input sequence
- Self-attention allows us to associate it with fruit in the following sentence:
-
When calculating attention, there are components:
-
A query matrix , consisting of query vectors
- represents a vector associated with a single input word
-
A key matrix , consisting of key vectors
- represents a vector associated with a single input word
-
A value matrix , consisting of key vectors
- represents a vector associated with a single input word
-
- Specifically, each individual matrix is the result of matrix multiplication between the input embeddings and matrices of trained weights:
- These weight matrices include , , and
-
Again, , , and refer to identical words of a sequence
- However, the values associated with , , and are different
- This is because , , and are weight matrices learned during training
- The formulas for , , and are defined below:
-
The example below has the following properties:
- Translating a sentence with words: hello and world
-
Each word embedding vector has a length of
- Implying, there are words in our vocabulary
-
Each , , and is a matrix
- Where, is an adjustable hyperparameter
- For now, we'll decide to assign
- Each , , and has a length of

- Notice, is the result of multiplying and together
- Notice, is the result of multiplying and together
- Notice, is the result of multiplying and together
Steps for Calculation Self-Attention in the Encoder
-
At a high level, a self-attention block does:
- Start with trained weight matrices , , and
-
Compute embeddings to determine how similar or previous activations are to input words and output words
- Roughly, represents embeddings of output words
- Roughly, and represent embeddings of input words
- In other words, learns patterns from our output sentence
- And, and learns patterns from our input sentence
-
Convert these similarity scores to probabilities
- This is because probabilities are easier to understand
-
At a lower level, a self-attention block does:
- Receives trained weight matrices , , and
-
Computes , , and :
-
Computes alignment scores by
- Here, we're looking for keys (input words) that are similar with our query (output word)
- Divide alignment scores by for more stable gradients
-
Pass values from our previous step through a softmax function
- This formats each alignment score as a probability
-
Compute dot product of to get matrix
- Here, represents our attention scores
- Roughly, represents how similar words from and are
- Multiplying softmax values by represents weighting each value by the probability that matches the query
Understanding Dimensions of , , and
- Suppose we're translating an English sentence to a German sentence
-
has the following dimensions:
- Number of rows number of words in the German sentence
- Number of columns a proposed length of the embedding
-
has the following dimensions:
- Number of rows number of words in the English sentence
- Number of columns a proposed length of the embedding
-
has the following dimensions:
- Number of rows number of words in the English sentence
- Number of columns a proposed length of the embedding
-
has the following dimensions:
- Number of rows number of words in the German sentence
- Number of cols number of words in the English sentence
-
has the following dimensions:
- Number of rows number of words in the German sentence
- Number of columns a proposed length of the embedding
- Here, is an adjustable hyperparameter
- Mathematically, these matrices are denoted as the following:
Calculating Self-Attention in the Encoder
-
, , and are simply abstractions that are useful for calculating and thinking about attention
- However, they are not attention scores themselves
- Each row of , , and are associated with an input word
- Meaning, , , and refer to the input word
- For now, let's focus on calculating the attention scores for the first word relative to the other words in the sentence (i.e. )
-
To calculate attention scores, we just take the dot product of
- This determines how relevant word is to word
-
The following diagram illustrates computing attention scores for:
- and
- and

-
Next, we'll normalize the attention scores by:
-
Dividing them by
- This leads to having more stable gradients
-
Then, passing those outputs through the softmax function
- The softmax function formats values as probabilities
- Thus, the output determines how much each word will be expressed for this input word
-
Computing the dot product of the softmax value and each
- This keeps relevant words and drowns out irrelevant words
-

- The steps can be condensed using matrix multiplication
- Thus, each row of is a vector for each word
- Again, represents the attention scores
- The following computes self-attention on and :

Improving Self-Attention with Multi-Headed Attention
- The transformer paper refined the self-attention layer by adding a mechanism called multi-headed attention
-
This improves the accuracy and performance of self-attention:
-
Accuracy:Different sets of , , and can learn different contexts and patterns in the sentence- We'll know it refers to fruit here:
Performance:Simply splitting , , and into smaller heads allows us to parallelize matrix multiplication and other computations on these heads
-
-
Without using multi-headed attention, self-attention will weight always assign the most attention to itself
- Consequently, it becomes useless
- Which is why we include different sets of heads
- Then, we'll be able to pick up on more interesting contexts
- Although additional sets of queries/keys/values are added, they can be processed in parallel with each other
-
The number of sets of queries/keys/values are determined by the number of attention heads
- This number is an adjustable hyperparameter
- For future examples, we'll assign this number , since this is the default number specified in the transformer paper
- The mult-headed attention mechanism follows the same steps as the steps in self-attention
-
However, multi-headed attention layer makes a few adjustments:
- Receives trained weight matrices , , and
-
Compute sets of , , and :
- Computes attention scores by
- Divide attention scores by for more stable gradients
- Pass the values in the previous step through the softmax function
- Compute dot product of to get matrix
- Stack the matrices together
- Multiply stacked matrix by another trained matrix to get

Defining the Masked Multi-Headed Attention Blocks
- The masked multi-headed attention block is essentially the same as an attention block
- However, the decoder must receive the information from the encoder
- Otherwise, we wouldn't have learned anything from the encoder
-
Therefore, the masked multi-headed attention block receives:
Information from encoder:all of the words from the english sentenceInformation from previous decoder layers:previous words in the translated sentence
- Thus, the masked multi-headed attention block masks upcoming words in the translated sentence by replacing them with
- Then, the attention network won't use them
Training Multi-Headed Attention Blocks
- , , and are trained and used in the encoder's multi-headed attention block
-
Then, and are passed to the decoder's masked multi-headed attention block
- In the multi-headed attention block, its own individual is trained
-
Lastly, the same and are passed again to the decoder's second multi-headed attention block
- The masked multi-headed attention block passes its to this multi-headed attention block
- This is a crucial step in explaining how the representation of two languages in an encoder are mixed together
-
In summary, there are matrices trained
- One is trained and used in the encoder
- Another is trained and used in the decoder
-
And, there is only and matrix trained
- They are trained and used in the encoder and decoder
Illustrating Multi-Headed Attention after Training
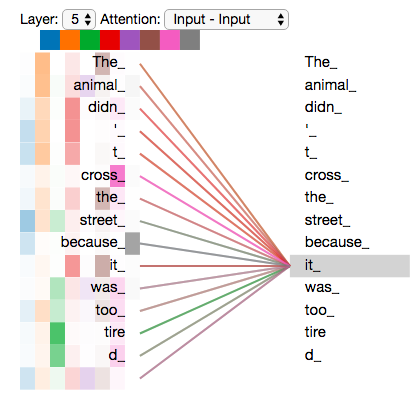
- After calculating each of the heads, we can refer to the attention heads relative to individual words to determine what each head focuses on
- In the following example, we encode the word it
- Notice, one attention head focuses most on the animal
- Another attention head focuses on tired
- In a sense, the model's representation of the word it bakes in some of the representation of both animal and tired

- In the above example, notice how we're only focused on the and heads
- By comparing particular heads with each other, we can get a decent idea about what other words each head focuses on relative to an individual word
- Notice, if we focus on all of the heads, any analysis becomes less interpretable:
Illustrating the Encoder and Decoder during Training
- The input of the encoder is an input sequence
- The output of the encoder is a set of attention vectors and
- These matrices are used by the decoders in its attention layers
- This helps the decoder focus on appropriate places in the input sequence
- Refer here for more detailed illustrations of the encoder and decoder
Applications of a Transformer Model
- Automatic text summarization
- Auto-completion
- Named entity recognition (NER)
- Question answering
- Machine translation
- Chat bots
- Sentiment analysis
- Market intelligence
- Text classification
- Character recognition
- Spell checking
Popular Types of Transformers
-
GPT-3
- Stands for generative pre-training for transformer
- Created by OpenAI with pre-training in 2020
- Used for text generation, summarization, and classification
-
T5
- Stands for text-to-text transfer transformer
- Created by Google in 2019
- Used for question answering, text classification, question answering, etc.
-
BERT
- Stands for bidirectional encoder represeentations from transformers
- Created by Google in 2018
- Used for created text representations
tldr
- The positional encoding vectors find patterns between positions of words in the sentences
- The attention layers find patterns between words in the sentences
- Normalization helps speed up training and processing time
- Multi-headed attention layers only involve to matrix multiplication operations
-
Multi-headed attention improves both performance and accuracy:
Accuracy:More heads imply more detectable patterns between wordsPerformance:These heads can be computed and trained in parallel using GPUs
- Multi-headed attention scores are formatted as probabilities using the softmax function
- The fully connected feed-forward layer in the encoders and decoders are trained using ReLU activation functions
-
Roughly, represents embeddings of output words
- learns patterns from our output sentence
-
Roughly, and represent embeddings of input words
- and learns patterns from our input sentence
- represents how similar words from and are
- The encoder and decoder use the same and
- The encoder and decoder has its own
References
- Stanford Deep Learning Lectures
- Stanford Lecture about LSTMs
- Lecture about Self-Attention in NLP
- Lecture about Multi-Headed Attention in NLP
- Lecture about Types of Attention in NLP
- Defining the Use and Architecture of Transformers
- Illustrating the Architecture of Transformers
- Paper about Transformer Models
- How Attention is Calculated During Training
- Intuition behind Positional Encoding Vectors
- Post about Positional Encoding Vectors
- Post about Attention Mechanism
- Detailed Description about Self-Attention
- Paper about Alignment and Attention Models