When is Concurrency Useful in Python?
-
Concurrency can help solve two types of problems:
- CPU-bound operations
- I/O-bound operations
-
Improving performance of these operations involves:
I/O-bound:Finding ways to overlap time spent waitingCPU-bound:Finding ways to do more computations in the same amount of time
- In Python, a good solution of concurrency for one operation may not work well for the other
Describing Concurrency in Python
- Concurrency in CPython is hindered by the GIL
-
CPython supports the following for a single process:
- CPU-bound threads can't run concurrently
- I/O-bound threads can run concurrently
- CPython allows multithreading for I/O-bound threads
-
Therefore, we should apply the following:
- Multithreading for I/O-bound threads
- Multiprocessing for CPU-bound threads
-
As a result, we achieve the following:
- Lightweight, concurrent I/O-bound threads
- Heavyweight, parallelized CPU-bound threads
Different Approaches of asyncio and threading
- Both
asyncioandthreadinginvolve tasks and threads - They differ by how their threads and tasks take turns
-
Specifically, the two libraries involve the following:
threadinginvolves pre-emptive multitaskingasyncioinvolves cooperative multitasking
Motivating Pre-Emptive Multitasking
- The
threadinglibrary involves pre-emptive multitasking - Pre-emptive multitasking ensures each process with a regular slice of CPU time
- This is done by the operating system
-
As a result, the OS is responsible for the following:
- The OS pauses threads
- The OS resumes threads
- The OS switches between threads
- Consequently, we can't influence when threads should switch
- Meaning, a switch could happen during a trivial
- However, this is usually not an issue
Motivating Cooperative Multitasking
- The
asynciolibrary involves cooperative multitasking - Cooperative multitasking ensures each task announces when to give up CPU time
- As a result, some of the responsibilites handled by the OS are transitioned to the user
- Meaning, we gain the potential benefit of choosing when to switch between tasks
Illustrating the Options of Concurrency
| Concurrency Type | Python Package | Switching Decision | Number of Processors |
|---|---|---|---|
| Pre-emptive multitasking | threading |
The OS decides when to switch tasks (external to Python) | |
| Cooperative multitasking | asyncio |
The tasks decide when to give up control (internal to Pythion) | |
| Multiprocessing | multiprocessing |
The processes all run at the same time on different processors | Many |
Option 1: Multithreading for I/O
-
The benefits are the following:
- Very fast
- Concurrent
-
The disadvantages are the following:
- Amount of code can grow quickly
- Need to worry about raceconditions
- Need to worry about deadlocks
- Difficult to debug
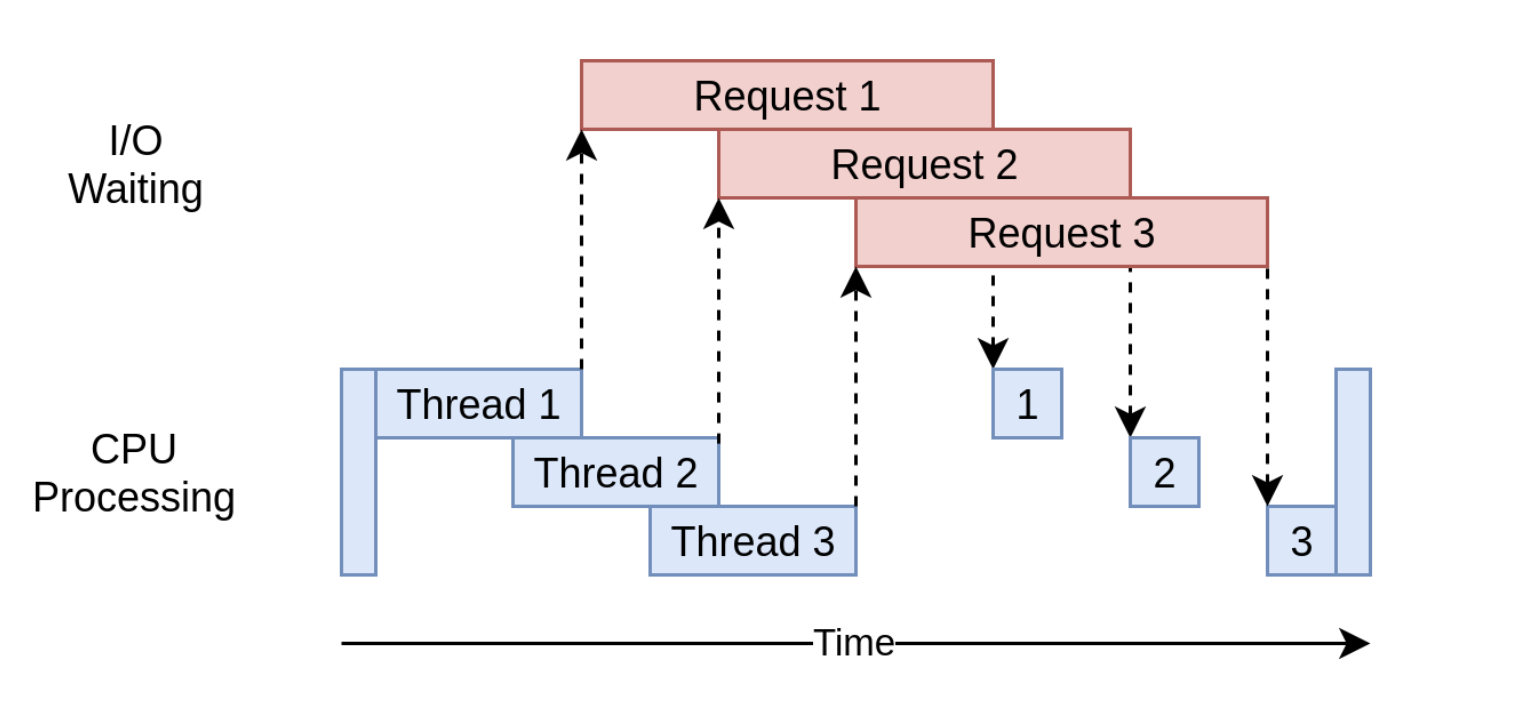
- An example of multithreaded code:
>>> from concurrent.futures import ThreadPoolExecutor
>>> from requests import Session
>>> import threading
>>> loc = threading.local()
>>> def get_session():
... if not hasattr(loc, 'session'):
... loc.session = Session()
... return loc.session
>>> def download_site(url):
... session = get_session()
... with session.get(url) as resp:
... print('Finished reading site')
>>> def download_all_sites(sites):
... with ThreadPoolExecutor(max_workers=5) as exec:
... exec.map(download_site, sites)
>>> sites = [
... 'https://www.jython.org',
... 'http://olympus.realpython.org/dice',
... ] * 80
>>> download_all_sites(sites) # Takes 3.7 secs- The execution diagram looks like this:
Option 2: Asyncio for I/O
-
The benefits are the following:
- Very fast
- Concurrent
- Single threaded (lightweight)
-
Very scalable
- Creating hundreds of tasks is more scalable than creating hundreds of threads for each session
-
The disadvantages are the following:
- Need non-blocking functions specific to asyncio
- One tasks can destroy performance for other tasks
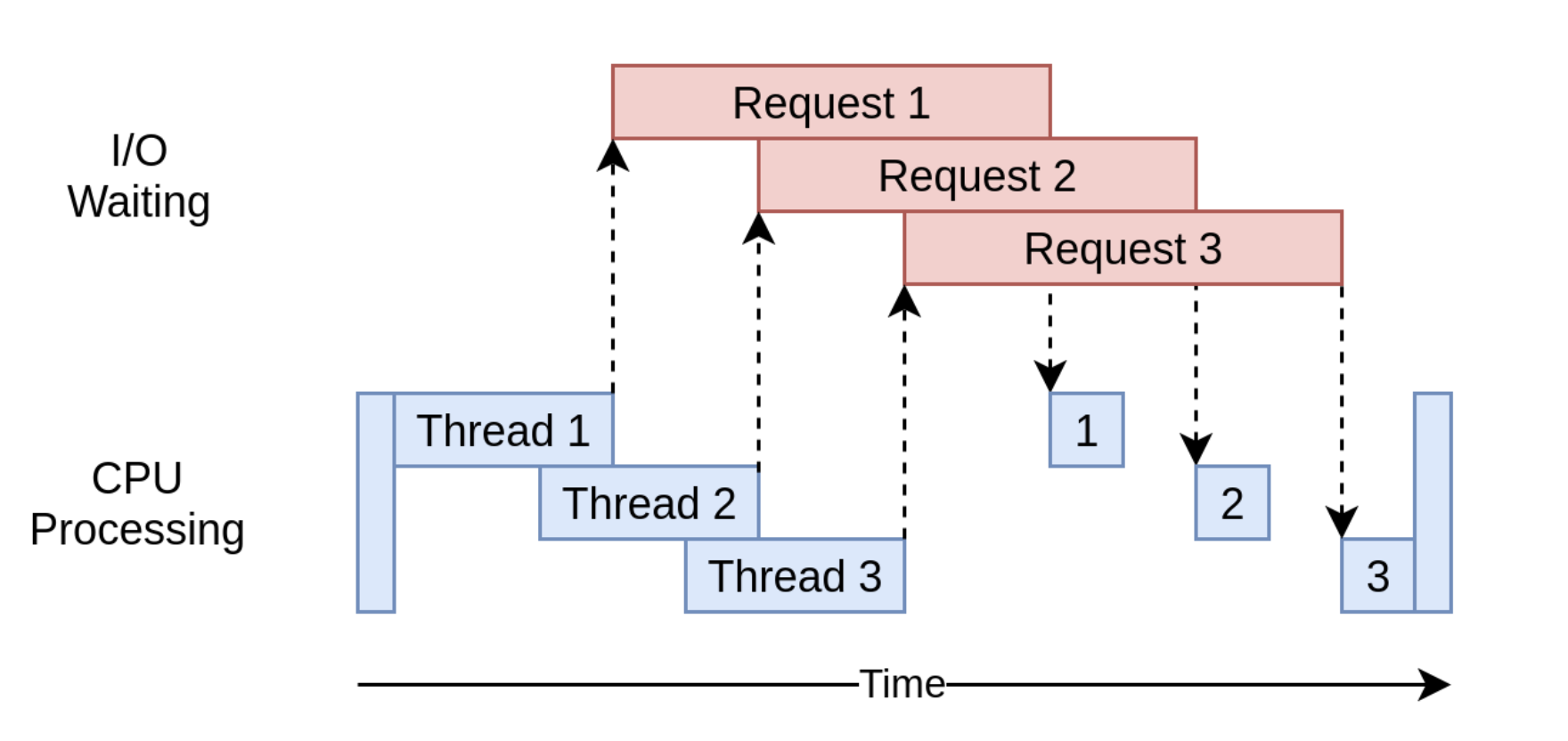
- An example of asynchronous code:
>>> from asyncio import create_task, gather, run
>>> from aiohttp import ClientSession
>>> async def download_site(session, url):
... async with session.get(url) as resp:
... print('Finished reading site')
>>> async def download_all_sites(sites):
... async with ClientSession() as sess:
... tasks = []
... for url in sites:
... t = create_task(download_site(sess, url))
... tasks.append(t)
... await gather(*tasks)
>>> sites = [
... 'https://www.jython.org',
... 'http://olympus.realpython.org/dice',
... ] * 80
>>> run(download_all_sites(sites)) # Takes 2.6 secs- The execution diagram looks like this:
Option 3: Multiprocessing for CPU
-
The benefits are the following:
- Parallelized
- Runs on multiple CPU cores
- Fairly intuitive
- Similar to synchronous code
- Fast for CPU-bound operations
-
The disadvantages are the following:
- Some strange components
- Slow for I/O-bound operations
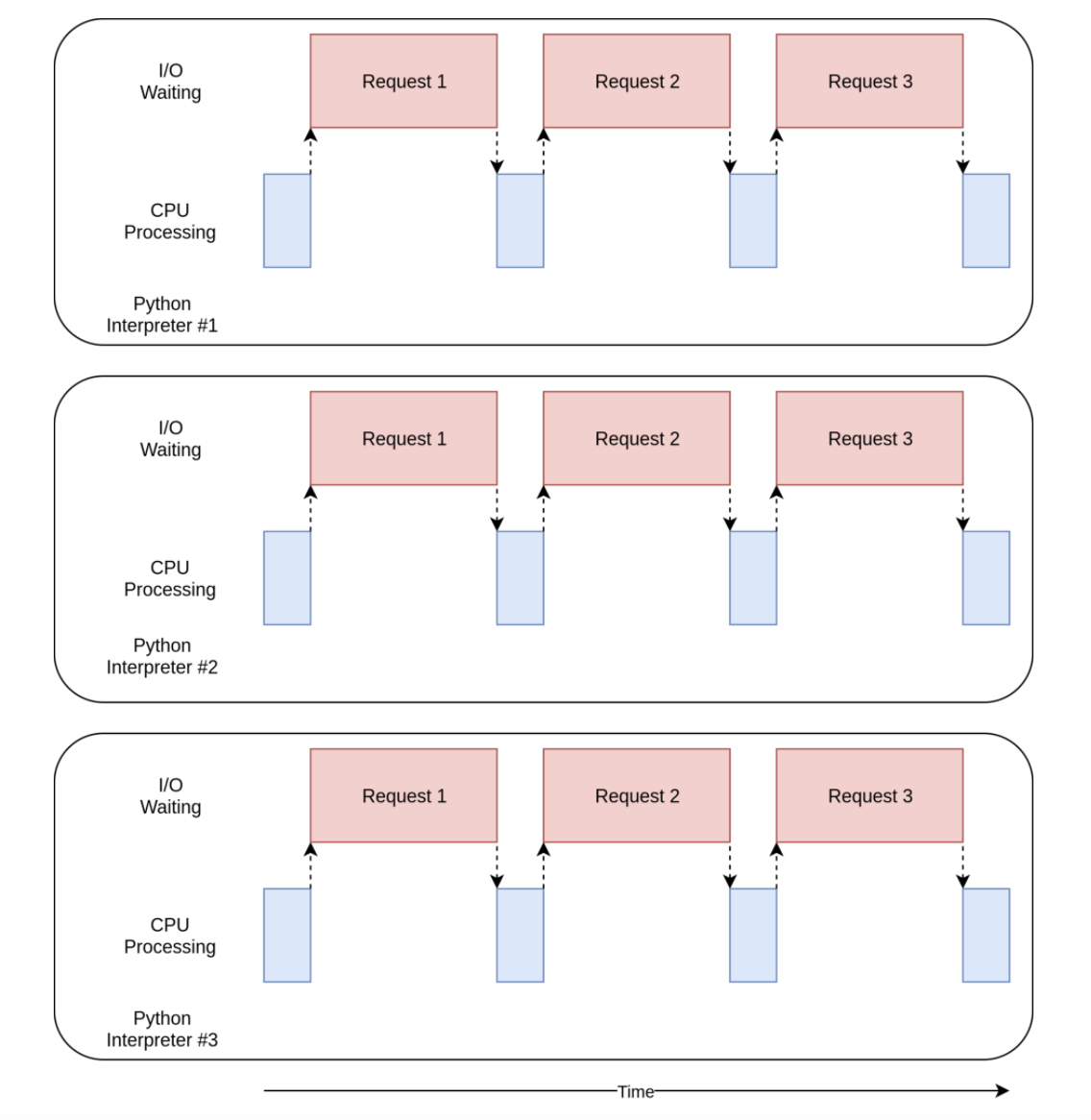
- An example of multiprocessed code:
>>> from multiprocessing import Pool
>>> def cpu_bound(num):
... return sum(i*i for i in range(num))
>>> def find_sums(nums):
... with Pool() as pool:
... pool.map(cpu_bound, nums)
>>> nums = [5000000+x for x in range(20)]
>>> find_sums(nums) # Takes 2.5 secs- The execution diagram looks like this:
References
Previous