History of BERT and Other NLP Models
- In the early stages of NLP, we simply wanted to predict the next word in a sentence
-
To do this, we used a continuous bag of words (CBOW) model
- This model is limited to classification based on the input words within a fixed-length sliding window
- Unfortunately, this model excludes the use of many useful context words and relationships with other words in the sentence
-
Then, ELMo was created in 2018 by researchers at the Allen Institute
- This model is a bidirectional LSTM
- Implying, words from the left and right are considered
- This model is able to entirely capture context words and relationships
- However, it still suffered from capturing context in longer sentences
-
Later in 2018, OpenAI introduced the GPT model
- There are versions of GPT: GPT-1, GPT-2, and GPT-3
- All three models are a transformer model
- This model only includes a decoder (no encoders included)
- This model only uses causal attention
- Unfortunately, each GPT model is only unidirectional
- Thus, we can't capture context both leftward and rightward of our target word in a sentences
-
In 2019, Google released the BERT model
- This model is a bidirectional transformer
- Implying, words from the left and right are considered
- This model is able to entirely capture context words and relationships
- This model only includes an encoder (no decoders included)
- This model doesn't suffer from capturing context in longer sentences
-
This model can do the following tasks:
- Next sentence prediction
- Multi-mask language modeling:
Introducing the T5 Model
- The T5 model could be used for several NLP tasks
- Its model (i.e. transformer) is similar to BERT
- Its pre-training (and training) strategy is similar to BERT
-
Similar to BERT, it makes use of two general concepts:
- Transfer learning
- Mask language modeling
- T5 proposes a unified framework attempting to combine many NLP tasks into a text-to-text format
- To do this, the T5 model utilizes transfer learning
-
The T5 model was trained on the dataset
- This data set has been open-sourced by the authors
- It contains of cleaned data scraped from the internet
Applications of the T5 Model
- Text classification
- Question answering
- Machine translation
- Text summarization
- Sentiment analysis
- And many other NLP tasks
Formatting the Inputs of the T5 Model
- Again, the T5 model is a unified framework combining many NLP tasks into a text-to-text format
-
This style of architecture differs from BERT
-
BERT is pre-trained base on the following two tasks:
- Masked language modeling
- Next sentence prediction
- Meaning, it must be fine-tuned for other tasks
- For example, we must slightly tweak the architecture if we're performing text classification or question answering
-
-
Contrarily, the text-to-text framework suggests using the same model, loss function, and hyperparameters for every NLP task
- Thus, the goal of T5 is to perform any NLP task without fine-tuning
-
This approach requires the inputs to be modeled so the model can recognize the task of interest
- As a result, each input must have its task included as a prefix
-
The following are examples of inputs formatted with task-prefixes:
-
Machine translation:
Input:'translate English to Spanish: Hello!'Ouput:'Hola!'
-
CoLA (grammar checking):
Input:'cola sentence: I had cat time!'Ouput:'unacceptable'
-
Sentiment analysis:
Input:'sst2 sentence: I had a great time!'Ouput:'positive'
-
- Then, the output is simply the text version of the expected outcome
- The following diagram illustrates the format of the input and output:

Describing the Pre-Training Strategy for T5
-
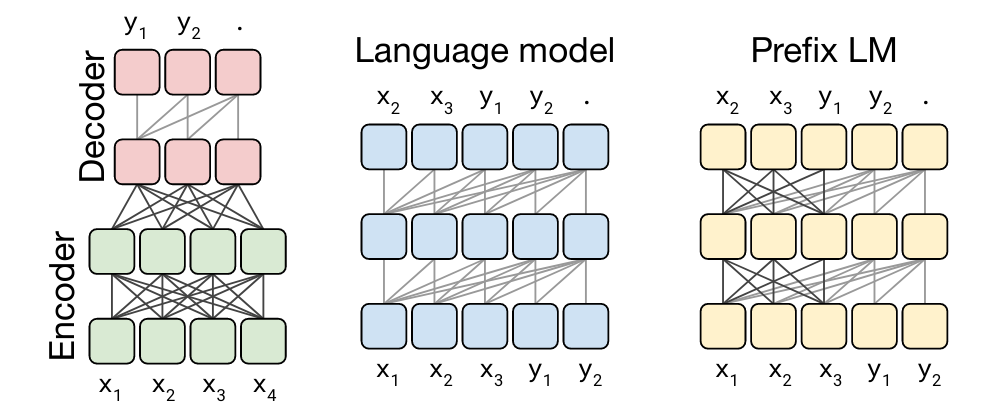
The T5 paper experimented with using three different architectures for pre-training:
- Encoder-Decoder architecture
- Language model architecture
- Prefix language model architecture
-
The encoder-decoder architecture is an ordinary encoder-decoder transformer
- The encoder uses a fully-visible attention mask
- This masking technique is also used in BERT
- Thus, every input token contributes to the attention computation of every other input token in the input sequence
- Then, the decoder is trained using causal attention
- Meaning, only the previous output tokens contribute to attention computation of the current output token in the output sequence
-
The language model architecture uses the attention mechanism
- It is an autoregressive modeling approach
- It is a mix between the the BERT architecture and language modeling approaches
- Based on various benchmarks, the best architecture is the encoder-decoder architecture
Defining the GLUE Benchmark
- The GLUE benchmark stands for general language understanding evaluation
- The GLUE benchmark is one of the most popular benchmarks in NLP
- It is used to train, test, and analyze NLP tasks
-
It is a collection of benchmark tools consisting of:
- A benchmark of nine different language comprehension tasks
- An ancillary data set
- A platform for evaluating and comparing the models
-
It is used for various types of NLP tasks:
- Verifying whether a sentence is grammatical
- Verifying the accuracy of sentiment predictions
- Verifying the accuracy of paraphrasing text
- Verifying the similarity between two texts
- Verifying whether two questions are duplicates
- Verifying whether a question is answerable
- Verifying whether a question is a contradiction
-
Usually, it is used with a leaderboard
- This is so people can see how well their model performs compared to other models on a dataset
-
The GLUE benchmark has the following advantages:
-
The GLUE benchmark is model-agnostic
- Doesn't matter if we're evaluating a transformer or LSTM
- Makes use of transfer learning
- Most research uses the GLUE benchmark as a standard
-
References
- Stanford Deep Learning Lectures
- Stanford Lecture about LSTMs
- Lecture about the T5 Transformer
- Lecture about Multi-Trask Training
- Lecture about the GLUE Benchmark
- Article about the T5 Transformer Model
- Description of T5 from Google AI Blog
- Textbook Chapter about Pre-Training Strategy
- Details about Preparing Inputs for Sentiment Analysis
- List of Tasks used in T5
- Paper about the T5 Transformer Model
- Paper about Alignment and Attention Models