Differentiating between Face Verification and Recognition
-
Face verification
- We input an image and a name ID
- A face verification method outputs if the image belongs to that claimed name ID
- Face verification is typically easier than face recognition
- This is because we only need to verify a single face to one ID
- Specifically, the accuracy needs to be around
-
Face recognition
- We input an image
- A face recognition method outputs if the image belongs to any name IDs
- Face recognition is typically harder than face verification
- This is because we need to verify a single face to many IDs
- Specifically, the accuracy needs to be around
Motivating One-Shot Learning
- Typically, we'll only have a single image associated with a name ID in our database
- Most face recognition systems need to learn from this one image
- Consequently, the learning algorithm trains on a small sample
- This problem is called the one-shot learning problem
- The one-shot learning problem is one of the main challenges for most face recognition systems
Describing One-Shot Learning
- Instead of learning the weights from a convolutional network, we want to learn a similarity function
- This similarity function measures the difference between two images
- Specifically, the similarity function is defined as the following:
- Where and are two different images
-
Where and are the activations of a fully-connected output layer from a siamese network
- We will talk about the siamese network in the next section
-
The similarity function returns:
- A small number if the two images are similar
- A large number if the two images are different
- This is defined as the following:
- Here, represents some threshold hyperparameter
- This is the root of all face verification problems
- For face recognition, we would need to calculate this similarity function on the input image and each image in our database
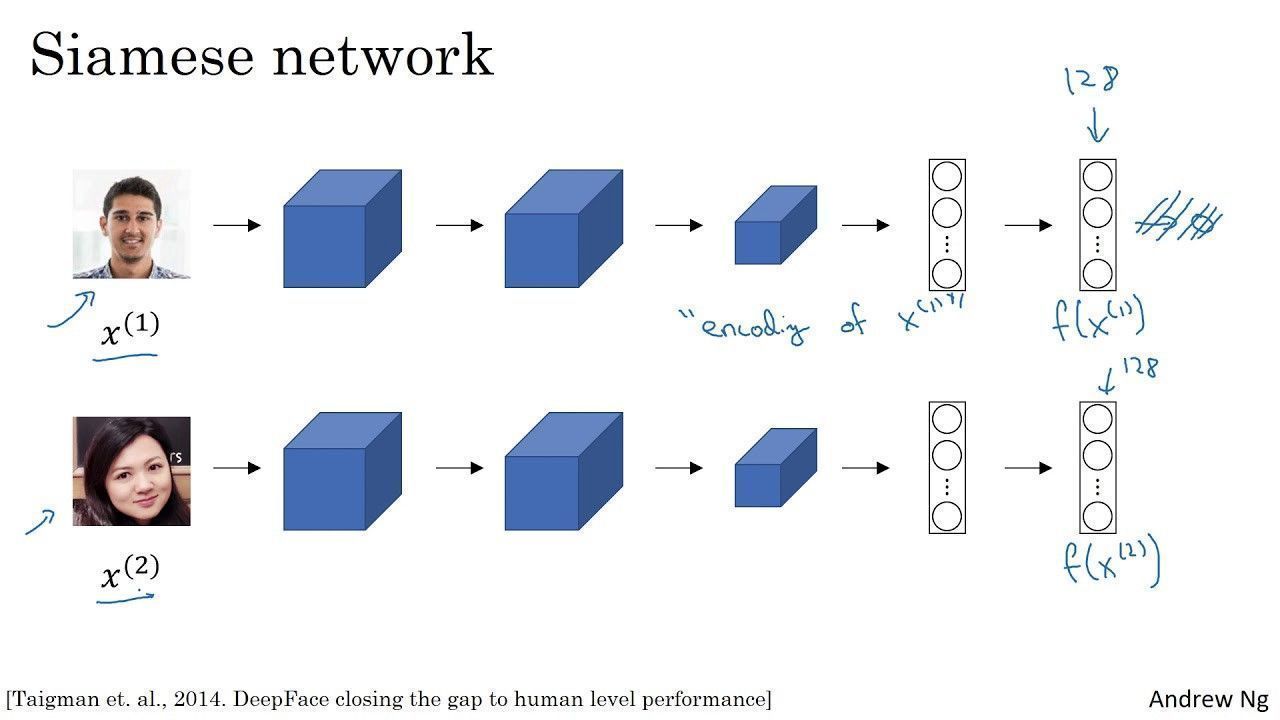
Introducing Siamese Network
- A siamese network is a convolutional network found in face recognition problems
- Roughly, a siamese network encodes an input image into a -digit vector
- Specifically, a siamese network architecture refers to running two different images on an identical network
- A siamese network is trained such that the similarity function ensures encodings (or output layer) of the same person return a small value
-
In other words, a siamese network learns parameters such that:
- If and are the same person, then is small
- If and are different people, then is large
- Formally, parameters of a siamese network define an encoding
- Formally, an input image will be encoded into a -digit vector
Defining the Triplet Loss Function
- A siamese network uses a triplet loss function
- The triplet loss function is defined as the following:
- Here, refers to the encoded activations of an anchor image
- Here, refers to the encoded activations of a positive image
- Here, refers to the encoded activations of a negative image
- An anchor image refers to an input image we want to test
- A positive image refers to a saved image that is the same person from the anchor image
- A negative image refers to a saved image that is not the same person from the anchor image
Describing the Triplet Loss Function
- The term triplet loss comes from always needing to train on three images at a time
- Therefore, we will need multiple pictures of the same person
- For example, we may need pictures for each person
- We want the encodings of the anchor image to be very similar to the positive image and very different from the negative image
- Formally, we want the following:
- This can also be written as the following:
- We can satisfy this equation by setting each term to :
- Obviously, we don't want our network to train our images such that our encodings become equal to
- Meaning, the encoding would be equal to the encoding of every other image
- Therefore, we need to modify the objective such that our terms are smaller than :
- We need to tune the hyperparameter to find the right threshold
- The hyperparameter is referred to as a margin
- Including will prevent our network from learning those trivial solutions
- We can reformulate the formula to be the following:
Example of the Triplet Loss Function
- Let's say we set
- Then, our output could be the following:
- We can see that these terms satisfy our triplet loss condition
- Obviously, we would prefer for the gap to be larger between our positive and negative images
- For example, we'd prefer the following at the very least:
- Alternatively, we could push the up or down
- However, we'd obviously prefer to satisfy both conditions
Choosing the Triplets , , and
- We don't want to randomly choose , , and
- If we randomly choose these images, then is easily satisfied
- Therefore, we'll want to choose triplets that are hard to train on when construction our training set
- Meaning, we want to choose , , and so that this is initially true early on in training:
tldr
- One-shot learning is a training algorithm
- Specifically, one-shot learning involves training on two images such that the similarity between the two images is minimized
- This similarity function is defined as the following:
- A siamese network is a convolutional network found in face recognition problems
- Roughly, a siamese network encodes an input image into a -digit vector
-
A siamese network learns parameters such that:
- If and are the same person, then is small
- If and are different people, then is large
- A siamese network uses a triplet loss function
- The triplet loss function is defined as the following:
- The term triplet loss comes from always needing to train on three images at a time
- Therefore, we will need multiple pictures of the same person
- We want the encodings of the anchor image to be very similar to the positive image and very different from the negative image
- We want to choose triplets that are hard to train on when construction our training set
References
Previous
Next