Differentiating between Face Verification and Recognition
-
Face verification
- We input an image and a name ID
- A face verification method outputs if the image belongs to that claimed name ID
- Face verification is typically easier than face recognition
- This is because we only need to verify a single face to one ID
- Specifically, the accuracy needs to be around
-
Face recognition
- We input an image
- A face recognition method outputs if the image belongs to any name IDs
- Face recognition is typically harder than face verification
- This is because we need to verify a single face to many IDs
- Specifically, the accuracy needs to be around
Describing Face Verification
- The training process of a face verification network is very similar to the training process of a face recognition network
- Specifically, we would still train a siamese network
- However, we add an extra layer after the embeddings
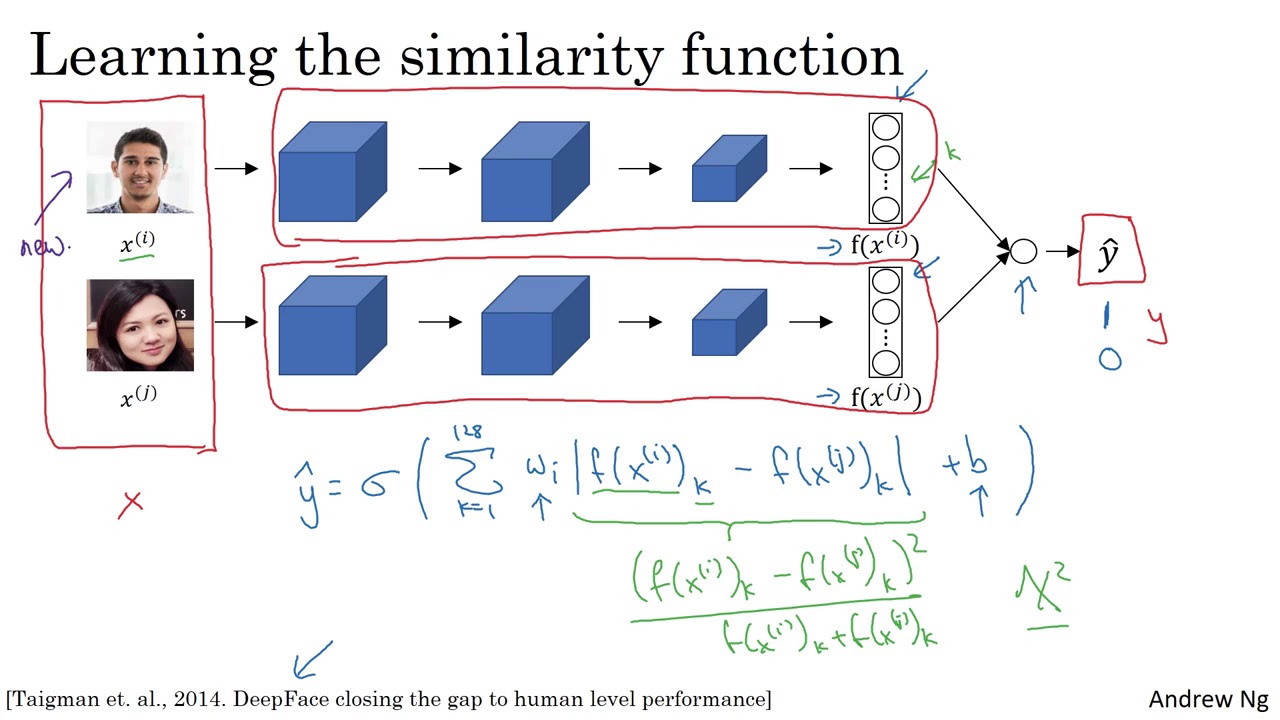
- This extra layer contains a single sigmoid neuron
-
Specifically, this output layer outputs:
- A if the two images are the same
- A if the two images are different
- Therefore, we are not using a triplet loss anymore
- Instead, we are using a cross-entropy loss function
Defining the Network
- The output of our network becomes a sigmoid function applied to the features
- These features aren't only the embeddings
- Instead, the activations become the following:
- Here, represents the component of the -digit vector
- Then, the output of our network becomes the following:
- We can use other variations of the term
- For example, we could use the similarity:
- There are many other variations of possible similarity functions
- Instead of training triplets, we are only training pairs of images
tldr
- The training process of a face verification network is very similar to the training process of a face recognition network
- Specifically, we would still train a siamese network
- However, we add an extra layer after the embeddings
- This extra layer contains a single sigmoid neuron
- The output of our network becomes a sigmoid function applied to the features
- These features aren't only the embeddings
- Instead, the activations become the following:
- Instead of training triplets, we are only training pairs of images
References
Previous
Next